
The Complete Reference for Multithreading in ChibiOS/RT
Introduction
ChibiOS/RT is the core of the ChibiOS embedded collection and it is commonly referred to as RT. It is a Real-Time Operating System (RTOS) specifically tailored for embedded applications with stringent time requirements. It simplifies the design of such applications by providing multithreading and a preemptive priority-based scheduler. This scheduler ensures that threads are executed based on their priority levels, allowing higher-priority threads to interrupt lower-priority ones when necessary. This feature makes ChibiOS/RT suitable for real-time applications that demand precise and predictable behavior. Moreover, the RTOS offers synchronization mechanisms like mutexes and semaphores, as well as virtual timers and asynchronous events to facilitate thread coordination.
This article builds on top of Mastering multithreading with ChibiOS: a beginner’s guide and delves into the details of thread scheduling in ChibiOS/RT. It focuses on how threads switch, the impact of thread priorities on scheduling, the effects of priority inversion, and guidelines for configuring the scheduler to optimize the RTOS performance.
Threads and multithreading
Multithreading 101
One of the key features of an RTOS, such as ChibiOS/RT and perhaps its most fundamental feature, is multithreading. But what exactly is a thread? We can think of a thread as a single path of execution: a sequence of instructions that the system executes in order. A thread typically starts with some initial configuration and then enters a loop, where it performs a series of periodic tasks indefinitely. This loop continues unless the application stops (e.g. the MCU is powered down) or the thread is terminated through software commands.
A thread is a continuous stream of code execution that can potentially run endlessly.
If we were to imagine a thread therefore, we could imagine it as straight arrow that starts at a point and extends indefinitely.

An RTOS like ChibiOS/RT enables multiple threads to operate in a parallel fashion, even on a single-core CPU. It achieves this by allocating CPU time to each thread according to specific rules. Hence, an RTOS is often referred to as a Scheduler, and the set of rules it uses to determine the execution order of threads is known as the Scheduling Strategy.
An RTOS allows for execution of multiple threads in a parallel fashion.
In ChibiOS/RT, threads have the capability to spawn additional threads, and they can also terminate. There are a variety of synchronization mechanisms available to manage these events. Returning to our arrow analogy, we might envision a multithreaded application as follows:
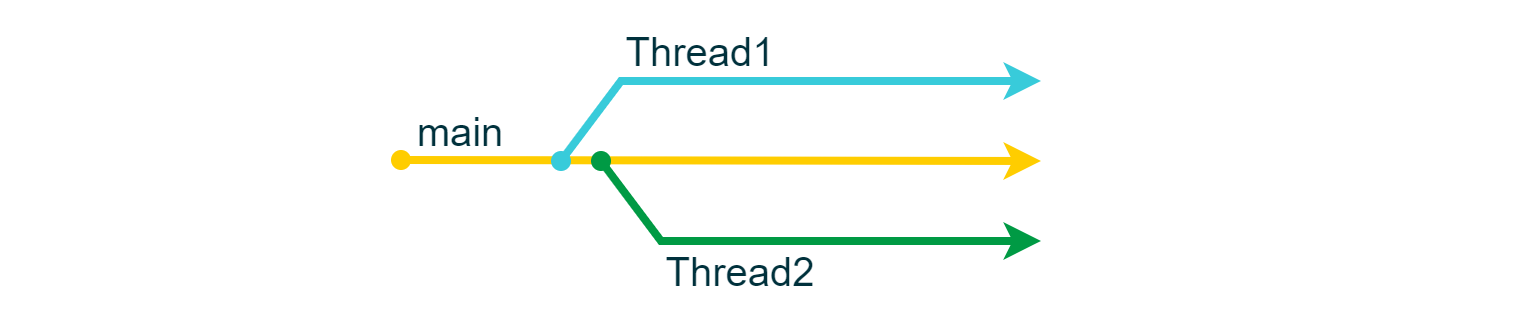
Here, the application consists of three threads: the main thread creates two additional threads, and all threads appear to operate independently of each other.
What is actually a thread in ChibiOS/RT?
In ChibiOS/RT, a thread comprises two essential components:
- Firstly, the Thread Function, which is a function that executes the designated tasks continuously.
- Secondly, the Working Area, also known as the Thread Stack, is an exclusive memory segment allocated for the thread’s use. This segment facilitates the thread’s autonomy and its size is determined by the thread’s requirements and the characteristics of the target platform.
Upon creation, each thread is assigned a Priority level and it has access to shared variables located in RAM, external to any thread stack. Additionally, it can access hardware resources, including CPU registers and I/O peripherals.
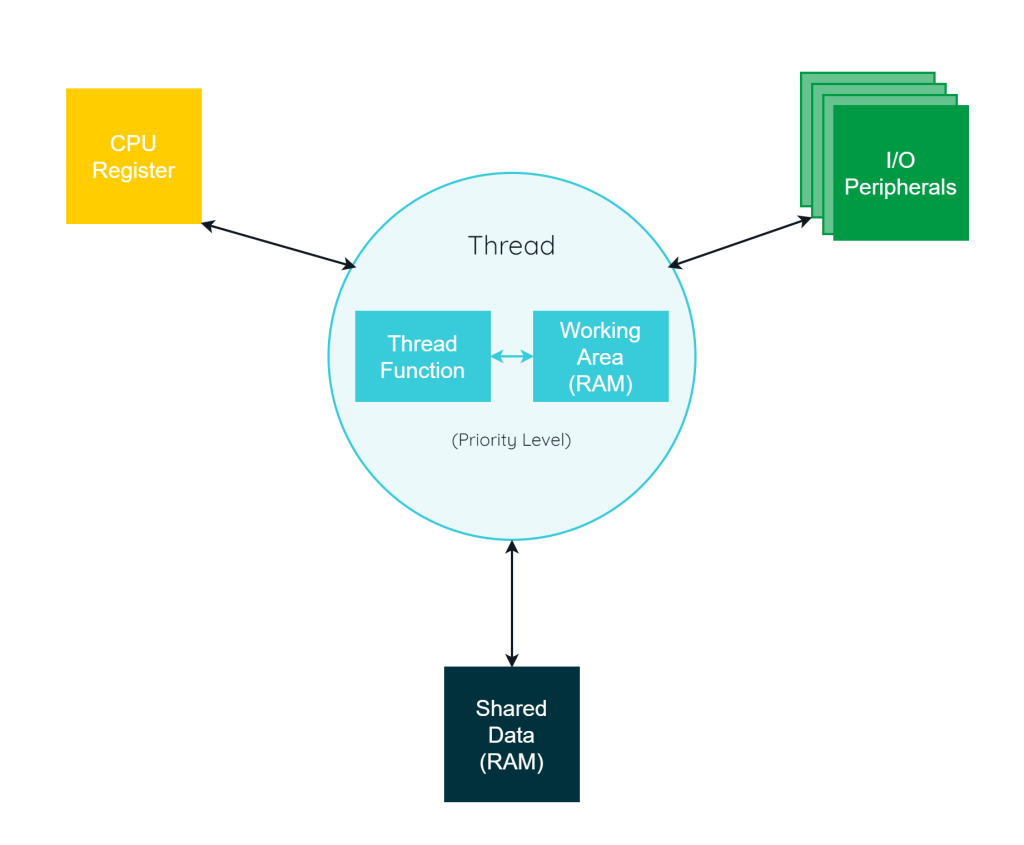
It’s important to distinguish between the Thread Function and the thread itself. The Thread Function merely defines the thread’s behavior. This distinction is evident from our exploration in the article Parametric Threads with ChibiOS, where we demonstrated the ability to instantiate multiple threads from the same Thread Function, each utilizing separate working areas.
ChibiOS/RT primarily supports two types of threads:
- Static Thread: This is a thread with a working area that is statically allocated during compile time.
- Dynamic Thread: This is a thread with a working area allocated at runtime from the heap or a memory pool.
While static threads are generally favored to prevent memory fragmentation, there are cases where dynamic allocation is necessary. ChibiOS/RT includes a comprehensive API to support dynamic thread allocation.
Consider the following code snippet, which illustrates how to allocate a new static working area for a thread with 128 bytes of usable space, referred to as waThread1. It also defines a Thread Function named Thread1 and, in the main function, it creates and starts the thread:
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
/* One-time setup for Thread1. */
// Your one-time code here
while (true) {
/* Periodic task for Thread1. */
// Your periodic action code here
chThdSleepMilliseconds(100);
}
}
int main(void) {
...
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO + 1, Thread1, NULL);
...
}
For readers already experienced with building applications using ChibiOS, this API will be familiar. It is assumed that you are reading this article to deepen your understanding of the scheduling dynamics. If you require a refresher, however, I recommend revisiting the section What is a Thread? from Mastering multithreading with ChibiOS: a beginner’s guide.
Consideration about the main and idle thread
In ChibiOS/RT, the main function is not just the entry point of the user application; it is also a thread, a special one at that. It initializes the scheduler by calling chSysInit(). When this occurs, the following actions are taken:
- The scheduler is initialized.
mainis registered as a thread with the priorityNORMALPRIO.- An additional thread, known as the
idlethread, is created and added to the scheduling list.
The main thread holds a unique status within ChibiOS/RT as it is the initial thread, both in declaration and in execution. As the entry point, it not only kicks off the scheduler but also has the primary responsibility of spawning the first set of additional threads. From there, these newly created threads have the ability to create further threads, forming a branching hierarchy of operations, all tracing back to the main thread. This lineage emphasizes the main thread’s pivotal role in the life cycle of the application’s multithreading process.
Another notable characteristic of the main thread is the way its Thread Stack is handled. Unlike other threads, whose stacks are explicitly declared within the C files, the main stack is implied in the project’s makefile, as shown below:
# Stack size to be allocated to the Cortex-M process stack. This stack is # the stack used by the main() thread. ifeq ($(USE_PROCESS_STACKSIZE),) USE_PROCESS_STACKSIZE = 0x400 endif
The idle thread is active by default and operates at IDLEPRIO, the lowest priority level in ChibiOS/RT. To maintain system efficiency, no other thread should share this priority. The idle thread is executed when no other threads are running. ChibiOS provides hooks to execute code upon entering and exiting the idle thread, allowing for operations such as disabling peripherals and reconfiguring the clock for low power consumption, though this comes at the cost of increased latency.
The idle thread can be disabled by modifying the configuration in chconf:
/** * @brief Idle thread automatic spawn suppression. * @details When this option is activated the function @p chSysInit() * does not spawn the idle thread. The application @p main() * function becomes the idle thread and must implement an * infinite loop. */ #if !defined(CH_CFG_NO_IDLE_THREAD) #define CH_CFG_NO_IDLE_THREAD FALSE #endif
In this scenario, the main function takes on the role of the idle thread, and its execution loop should be left empty.
Example of a multithreading application
Here is an illustration of a simple multithreading application in ChibiOS/RT, which comprises the main thread and an additional useful thread named Thread1, aside from the idle thread.
/*
* Thread1 related declarations
*/
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
/* One-time setup for Thread1. */
// Your one-time code here
while (true) {
/* Periodic task for Thread1. */
// Your periodic action code here
chThdSleepMilliseconds(100);
}
}
/*
* Main thread related declarations
*/
int main(void) {
/* Initial setup for the system. */
halInit();
chSysInit();
/* Starting Thread1. */
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO + 1, Thread1, NULL);
/* One-time setup for main. */
// Your one-time code here
while (true) {
/* Periodic task for main. */
// Your periodic action code here
chThdSleepMilliseconds(150);
}
}
In this example, placeholders indicate where to insert initialization and routine task code for each thread. It’s noteworthy that Thread1 and the main thread are assigned different priorities and operate at varying frequencies due to their respective sleep durations. A timing analysis of this setup will be conducted later to examine how these factors influence the scheduling.
How can multithread happen?
Context-switch: the magic behind multithreading
Microcontrollers often have single-core CPUs, yet they can run multiple code sequences seemingly in parallel. How is this possible? The key is the word “seemingly”. In reality, at any instant, only one thread actually runs. The job of the ChibiOS/RT is to rapidly and efficiently allocate CPU time among the threads, creating the illusion of concurrent execution.
The answer to our question posed at the beginning of this chapter is Context Switching. This involves temporarily stopping one thread and starting another. To grasp this concept, let us consider the following code
function void increase(int* p) {
int tmp = *p;
tmp++;
*p = tmp;
}
int main(void) {
int a = 0;
while(1) {
increase(&a);
}
}
Focusing on the instruction within the while loop, if we translate it into assembly for an ARM Cortex-M architecture, it would look like this:
; Function: increase
increase:
PUSH {LR} ; Push the return address onto the stack
LDR R1, [R0] ; Load the value of 'a' from the address in R0 into R1
MOV R2, R1 ; Move the value of R1 (a) into R2 (tmp)
ADD R2, R2, #1 ; Increment the value in R2 (tmp)
STR R2, [R0] ; Store the incremented value in R2 (tmp) back at the address in R0
POP {LR} ; Pop the return address off the stack
BX LR ; Return from the subroutine
; Main function loop
main:
LDR R0, =a ; Load the address of 'a' into R0
loop:
BL increase ; Call the increase function
B loop ; Infinite loop back to itself
This example demonstrates how the CPU employs its General-Purpose registers for operations, specifically R0 and R1 in this case. Alongside these, Special-Purpose registers are critical for code execution. Among those:
- Program Counter (PC): Directs the flow of execution. For instance, executing the line “
BL increase” causes the PC to jump to the first instruction of the “increase” function, rather than following a linear execution path. - Stack Pointer (SP): Essential for handling local variables and function calls. When a new local variable, like
tmp, is created, the SP adjusts to allocate space for it on the stack, pointing to the next available memory slot. - Link Register (LR): Holds the return address for subroutine calls. In this code, when
increaseis called viaBL increase,LRstores the return address. Afterincreasecompletes,LRis used to return to the instruction following the call in the main function, ensuring a smooth continuation of the program flow.
Like those, other Special Purpose registers are involved, directly or indirectly, in the code execution. Which brings us to the next statement
The values contained in the CPU (Special-Purpose and General-Purpose) registers represent the context of a thread or process that is currently being executed by the CPU.
So, let’s define the Current Execution Context (or simply Context) as the combined value of several CPU registers. It is important to notice that the registers which are crucial to the Context depends on the architecture in use: as example, In the ARM Cortex-M architecture, during a context switch, it is not typically necessary to manually save the contents of registers R0 to R3. This is because these registers are used as argument and return value registers and are not expected to be preserved across function calls. They are considered “scratch” registers or volatile registers. Additionally, if the MCU is equipped with a Floating Point Unit (FPU) – a dedicated hardware unit designed for floating-point calculations – the context saved during a switch will also include the registers of the FPU.
The context switch is essentially the act of saving the current thread’s context into memory and loading the context of the next thread. This allows the next thread to resume exactly where it left off during its last suspension, ensuring seamless task switching.
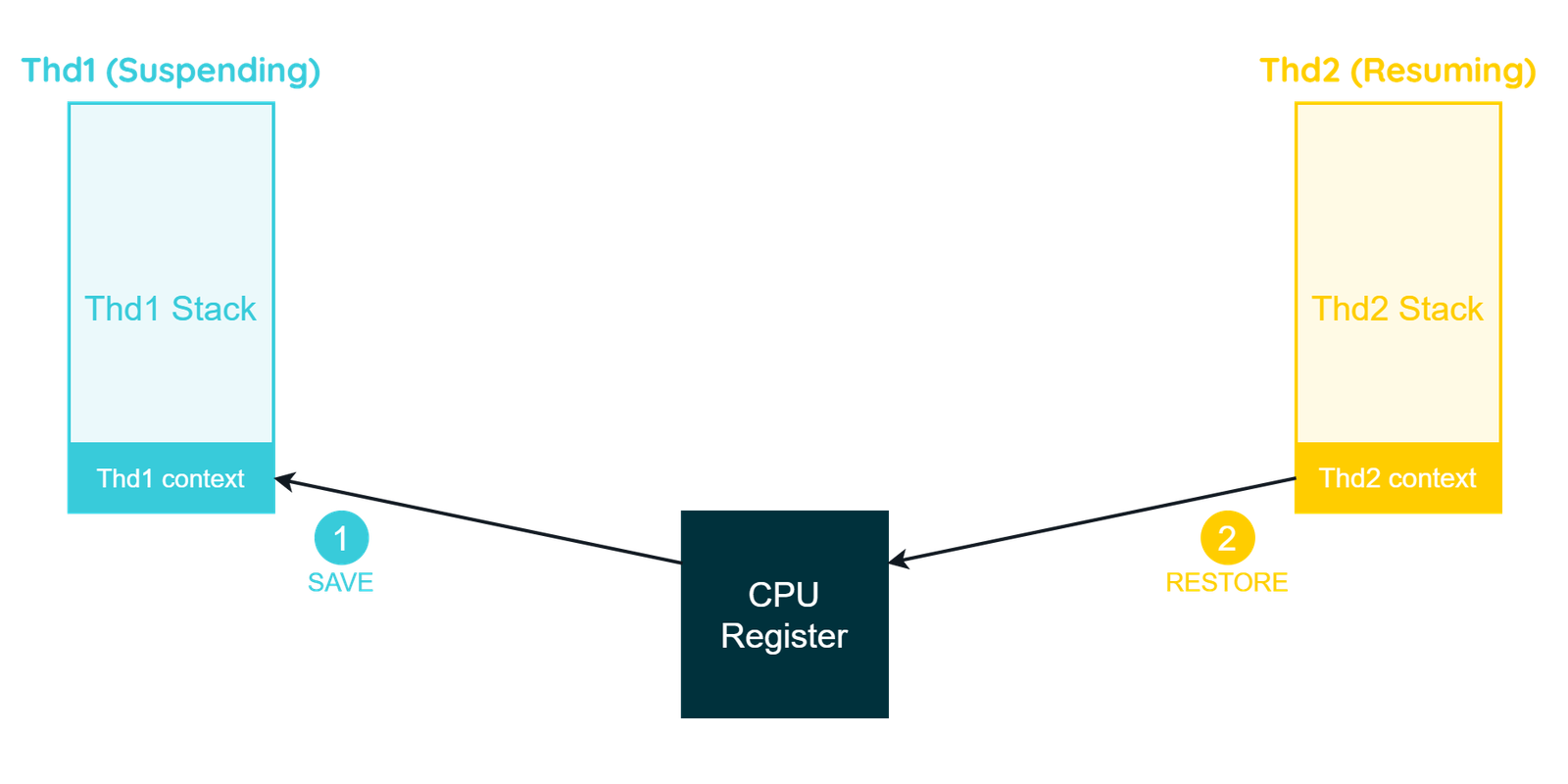
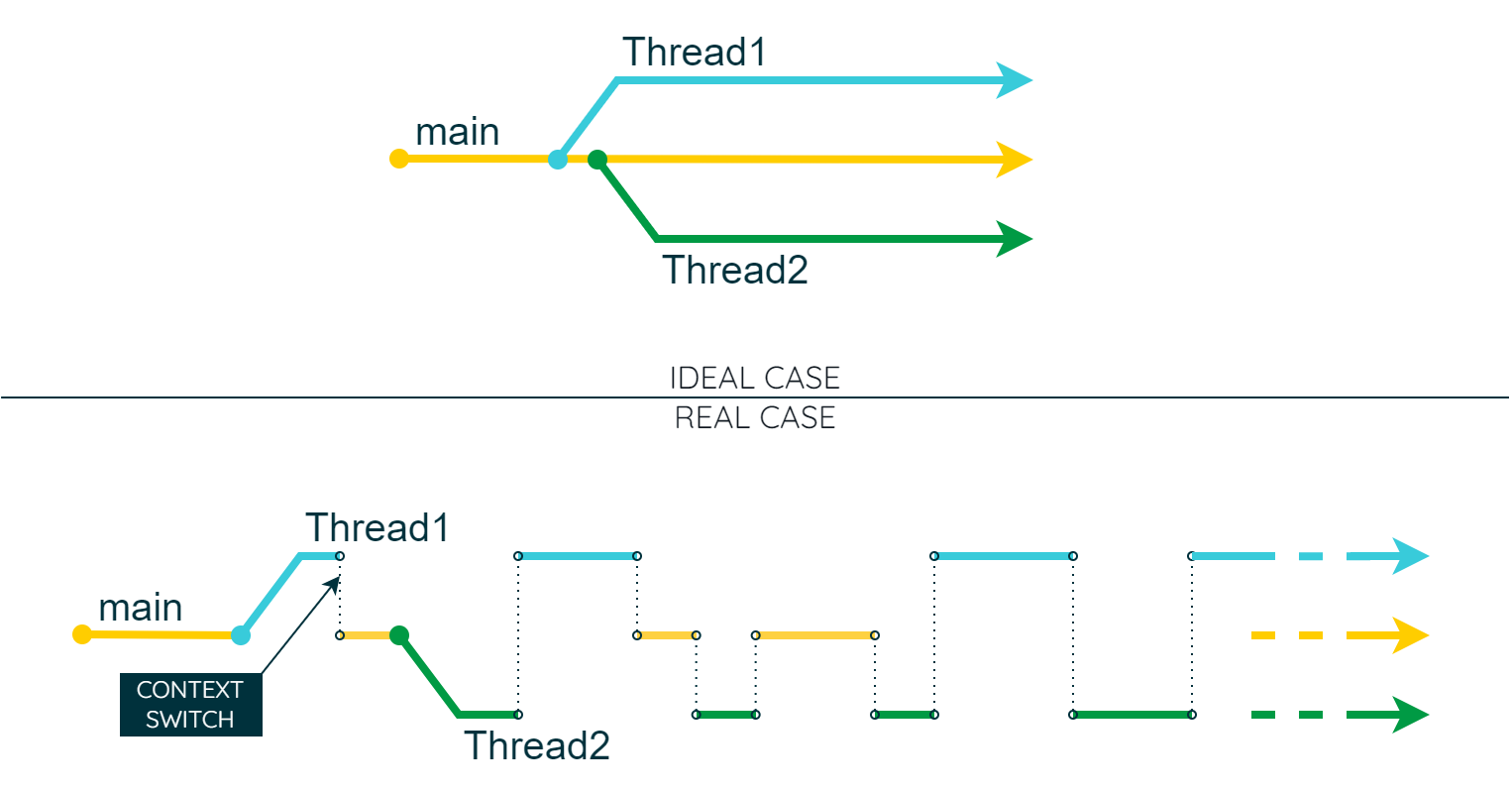
Equipped with this comprehensive set of new insights, we can now update our depiction of a multi-threaded application to be more accurate and realistic.
But were exactly is the context saved? In ChibiOS/RT, when we define a static working area using the THD_WORKING_AREA API, we provide two parameters: a name and a pointer to the working area, and the size in bytes for the thread’s use, mainly for automatic variables and stack frames.
static THD_WORKING_AREA(waThread1, 128);
However, the actual memory allocated is larger than the specified size. This is because ChibiOS/RT’s API automatically includes extra space for the ch_thread structure. This structure holds all the thread’s pertinent information, including its current state but also ample space to save the thread’s context during suspension: this explains why exactly each thread need his own working area.
Thread states
In general, a thread can occupy one of three primary states. Although ChibiOS offers a more complex state system, for our current discussion, the following simplifications are sufficient:
- Current: The thread is actively executing because the CPU is assigned to it.
- Ready: The thread is not running but is prepared to execute, waiting in the queue for its turn.
- Suspended: The thread is in a state of suspension, neither running nor prepared to run.
In a single-core application, only one thread can be in the ‘current’ state at any given time, actively utilizing the CPU. The user can employ APIs to transition a thread’s state to ‘Ready’ or ‘Suspended’. Additionally, the scheduler is equipped to automatically transition a thread to ‘Ready’ when specific conditions are fulfilled. Common triggers for such transitions include:
- The thread’s resume function is invoked by the user application.
- A timer reaches its set duration.
- An item is added to a queue.
- An event flag is set.
- A mutex that the thread was waiting on is released.
In ChibiOS/RT, the thread state model is indeed more nuanced, encompassing a broader spectrum of states:
/**
* @name Thread states
* @{
*/
#define CH_STATE_READY (tstate_t)0 /**< @brief Waiting on the ready list. */
#define CH_STATE_CURRENT (tstate_t)1 /**< @brief Currently running. */
#define CH_STATE_WTSTART (tstate_t)2 /**< @brief Just created. */
#define CH_STATE_SUSPENDED (tstate_t)3 /**< @brief Suspended state. */
#define CH_STATE_QUEUED (tstate_t)4 /**< @brief On a queue. */
#define CH_STATE_WTSEM (tstate_t)5 /**< @brief On a semaphore. */
#define CH_STATE_WTMTX (tstate_t)6 /**< @brief On a mutex. */
#define CH_STATE_WTCOND (tstate_t)7 /**< @brief On a cond.variable. */
#define CH_STATE_SLEEPING (tstate_t)8 /**< @brief Sleeping. */
#define CH_STATE_WTEXIT (tstate_t)9 /**< @brief Waiting a thread. */
#define CH_STATE_WTOREVT (tstate_t)10 /**< @brief One event. */
#define CH_STATE_WTANDEVT (tstate_t)11 /**< @brief Several events. */
#define CH_STATE_SNDMSGQ (tstate_t)12 /**< @brief Sending a message,in queue. */
#define CH_STATE_SNDMSG (tstate_t)13 /**< @brief Sent a message, waiting answer. */
#define CH_STATE_WTMSG (tstate_t)14 /**< @brief Waiting for a message. */
#define CH_STATE_FINAL (tstate_t)15 /**< @brief Thread terminated. */
/** @} */
The above definitions expand upon our initial overview. Here’s how they correspond:
CH_STATE_READYandCH_STATE_CURRENTalign with the ready and current states in our simplified model.CH_STATE_WTSTARTis the initial state of a new thread that is waiting to be added to the schedule, which you can achieve usingchThdCreateSuspended().CH_STATE_FINALrepresents a thread that has terminated.
The remaining states are variations of suspension, each with different conditions for reactivation. Of particular note are:
CH_STATE_SUSPENDED: A general suspension state, entered by invokingchThdSuspend()on a thread.CH_STATE_SLEEPING: Indicative of a thread that is temporarily inactive but scheduled to wake after a set period, typically initiated by calling one of thechThdSleep()and derived functions.
The reason behind idle
Understanding the sequence in which threads operate allows us to grasp the necessity of the idle thread. Consider a situation where all user threads are in a suspended state, each awaiting an event to proceed. In such instances, the CPU has no immediate tasks to perform, which is where the idle thread comes into play. It acts as a standby process, essentially filling the gap in CPU activity by executing a low-priority task that yields to any other thread as soon as it becomes ready.
The time spent in the idle thread is indicative of the CPU’s inactivity. By measuring the duration the CPU remains in this state within a specific time frame, we can determine the idle time percentage. This figure is a useful indicator of the application’s CPU usage efficiency. If the idle thread is active for a large portion of time, it suggests that the CPU has a considerable amount of untapped processing capacity, which could mean the application is not demanding or that the system is highly efficient.
Absolving to Real Time applications
Determinism: repeatability and predictability
ChibiOS/RT is a Real Time Operating System and as such it needs to possess certain characteristics. Indeed an RTOS stands out due to its ability to efficiently process data and respond to inputs within a guaranteed timeframe, often referred to as a deadline. The crucial aspect here is the assurance of response within this timeframe, stemming from the first most important characteristic of an RTOS: determinism. In deterministic systems, like in mathematics, there is no randomness. Determinism leads to two outcomes:
- Repeatability which means that given the same conditions, the RTOS will consistently produce the same outcome.
- Predictability which means that the behavior of the RTOS is well-known and can be precisely predicted, assuming the conditions are understood.
Low latency: preemptiveness and priorities
While determinism is what makes an OS Real Time capable, however the goodness of an RTOS falls on low latency or, in other words, the shortest deadline it can reliably meet. ChibiOS/RT achieves low latency with a fully-preemptive priority scheduling where each thread is assigned a priority and the order of execution is influenced by it.
In ChibiOS/RT each thread is assigned a Priority: this determines the order in which threads are executed, with higher priority threads being attended to first. Whenever a Thread at higher priority becomes ready, the current one is immediately suspended: this process, known as Preemption, ensures that higher priority threads are served with low latency.
It is important to notice that here is that, in ChibiOS/RT, priorities are specific numbers:
/**
* @name Priority constants
* @{
*/
#define NOPRIO (tprio_t)0 /**< @brief Ready list header priority. */
#define IDLEPRIO (tprio_t)1 /**< @brief Idle priority. */
#define LOWPRIO (tprio_t)2 /**< @brief Lowest priority. */
#define NORMALPRIO (tprio_t)128 /**< @brief Normal priority. */
#define HIGHPRIO (tprio_t)255 /**< @brief Highest priority. */
/** @} */
The idle thread is the only one set at IDLEPRIO. The main thread is automatically set at NORMALPRIO unless it acts as the idle thread. Thread priorities are relative, not absolute. For example, in a two-thread application with main and Thread1, Thread1‘ priority being NORMALPRIO + 1 or NORMALPRIO + 10 will not affect the order of execution. The only thing that matters is that Thread1‘ priority is higher than main‘s.
Interrupt Requests and Critical Zones
We’ve learned about threads, but what happens to them when an interrupt occurs? For instance, if a thread is put to sleep, what wakes it up?
Interrupt Requests can interrupt even the highest-priority thread. Imagine Interrupt Service Routines (ISRs) running at a priority above the operating system itself. Therefore, ISRs should not have blocking functions, as this can cause delays, making our application not real-time. In fact, ISRs capture events that are frequently used to reschedule and determine which thread will run next. A common example is the IRQ generated by a timer when a thread is put to sleep for a specific amount of time.
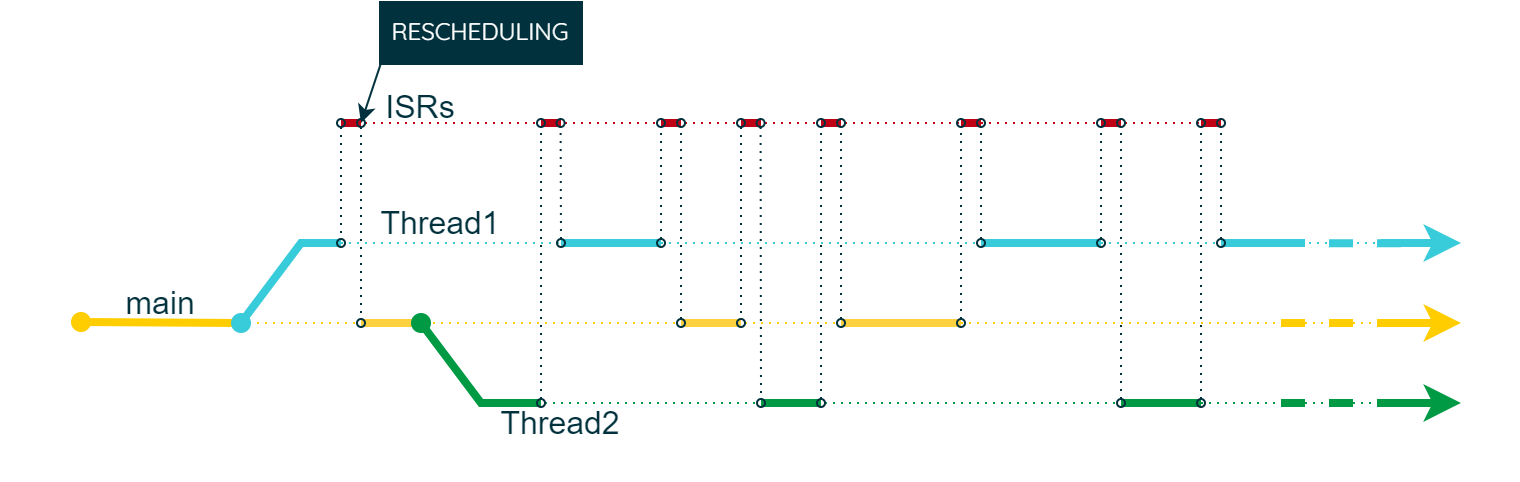
However, there are times when we don’t want interrupts to preempt critical code sections. In ChibiOS/RT, we can prevent this by using “critical zones.” We can protect code areas from IRQs and other threads using specific APIs. For example, the code below can be used in any thread to create a critical zone:
chSysLock(void); /* Your critical zone in thread context here. */ chSysUnlock(void);
This code needs to be used carefully as it can introduce latency on higher priority thread or ISRs. Similarly, we can create a critical zone in ISR context with this API:
chSysLockFromISR(void); /* Your critical zone in ISR context here. */ chSysUnlockFromISR(void);
So, who manages the ISRs in ChibiOS applications? ChibiOS/RT does. The RTOS provides an API for handling ISRs. ChibiOS/HAL uses this API to build device drivers that work efficiently with threads.
System tick and tick-less mode
To achieve precise deadlines, an RTOS utilizes a hardware timer for scheduling. ChibiOS/RT follows this approach, typically assigning one of the high-resolution timers to a special peripheral exclusively for the Scheduler, known as the System Tick (ST). The assignment of this timer is configured in the mcuconf.h file:
/* * ST driver system settings. */ #define STM32_ST_IRQ_PRIORITY 8 #define STM32_ST_USE_TIMER 2
Three additional important configurations are set in chconf.h:
CH_CFG_ST_RESOLUTION: Defines the precision of the hardware timer used. A high-precision timer is recommended for more accurate time measurement and better control over task scheduling and delays, improving system efficiency and responsiveness.CH_CFG_ST_FREQUENCY: Determines the system tick frequency. In tick mode, this sets frequency of interrupt requests generated by the timer. This setting also defines the smallest time unit the RTOS can manage.CH_CFG_ST_TIMEDELTA: Indicates whether the system operates in traditional or tick-less mode. A value of 0 means traditional mode; a value of 2 or higher means tick-less mode and sets the minimum safe number of ticks for timeout directives.
/** * @brief System time counter resolution. * @note Allowed values are 16, 32 or 64 bits. */ #if !defined(CH_CFG_ST_RESOLUTION) #define CH_CFG_ST_RESOLUTION 32 #endif /** * @brief System tick frequency. * @details Frequency of the system timer that drives the system ticks. This * setting also defines the system tick time unit. */ #if !defined(CH_CFG_ST_FREQUENCY) #define CH_CFG_ST_FREQUENCY 10000 #endif /** * @brief Time delta constant for the tick-less mode. * @note If this value is zero then the system uses the classic * periodic tick. This value represents the minimum number * of ticks that is safe to specify in a timeout directive. * The value one is not valid, timeouts are rounded up to * this value. */ #if !defined(CH_CFG_ST_TIMEDELTA) #define CH_CFG_ST_TIMEDELTA 2 #endif
Traditional RTOS designs use a tick-based approach, where the system clock generates periodic interrupts (ticks) for task scheduling. With the above configuration (CH_CFG_ST_FREQUENCY equal to 10000), this interrupt would occur every 100µs. However, ChibiOS/RT also offers a tick-less mode.
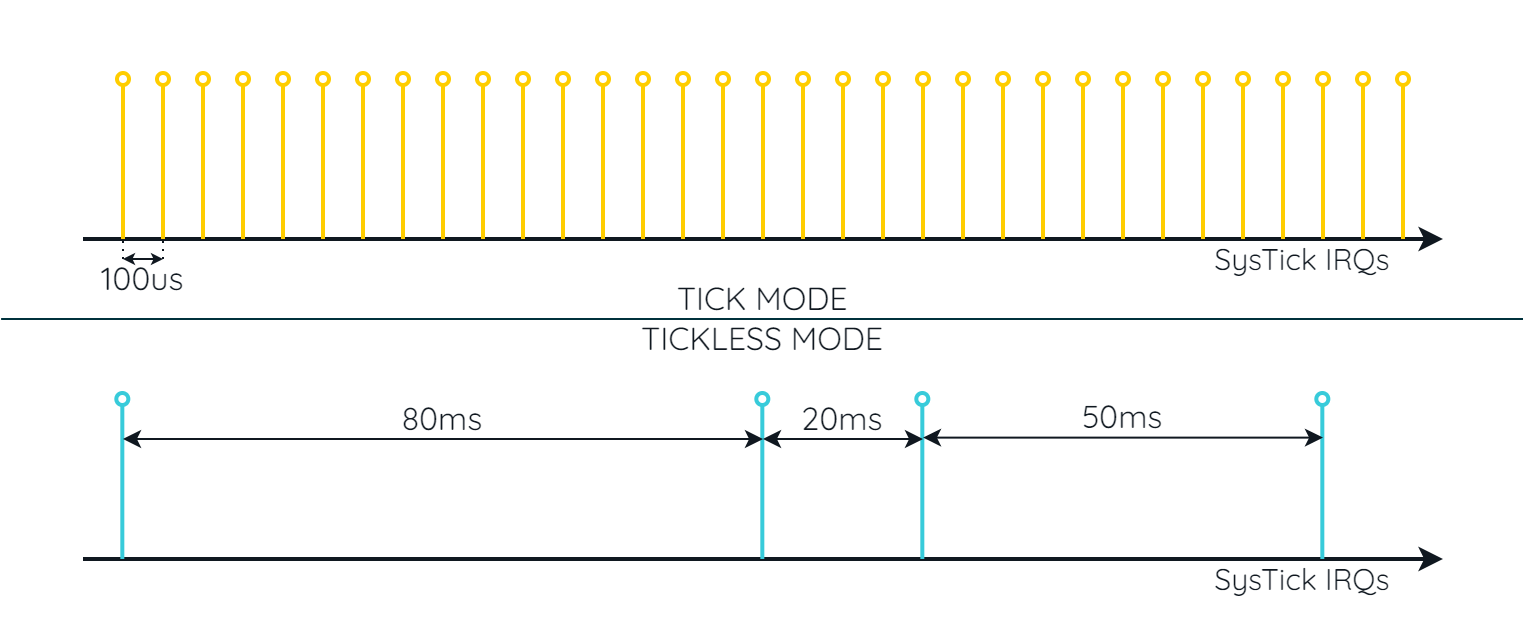
In tick-less mode, ChibiOS/RT forgoes the need for periodic tick interrupts for scheduling. Instead, the RTOS reconfigures the timer to generate interrupts only at task deadlines, thus avoiding superfluous IRQs. Rather than waking up at regular intervals to check for needed context switches (as in traditional mode), the system in tickless mode wakes only when necessary to perform a task. This mode is especially beneficial for low-power applications or in situations where minimizing power consumption is crucial.
Blocking APIs
ChibiOS provides various APIs that are crucial for thread management. Among these are specific APIs identified as blocking from the perspective of the calling thread. These APIs are designed to implicitly suspend the calling thread, and plan ahead to resume the thread at a subsequent moment when certain conditions are met. To aid our upcoming discussion, we will list and explain some of these APIs, focusing on their impact on the calling thread.
Sleep functions
These APIs are preferred for simple applications, as they suspend a Thread for a specific time. They are essentially redefinitions of the chThdSleep(): while this function accepts an integer representing the system tick clock value these redefinitions specify delays in second, milliseconds or microseconds.
/** Delays thread for specified seconds, considering system tick clock and value limits. */ #define chThdSleepSeconds(sec) chThdSleep(TIME_S2I(sec)) /** Delays thread for specified milliseconds, considering system tick clock and value limits. */ #define chThdSleepMilliseconds(msec) chThdSleep(TIME_MS2I(msec)) /** Delays thread for specified microseconds, considering system tick clock and value limits. */ #define chThdSleepMicroseconds(usec) chThdSleep(TIME_US2I(usec))
These functions set an alarm using a hardware timer and suspend the calling thread. When the alarm expires, it triggers an IRQ, and ChibiOS/RT adds the thread back to the ready list. If it’s the highest-priority thread, it resumes immediately. ChibiOS/RT uses a hardware timer for accurate scheduling. The state of the calling thread is set to CH_STATE_SLEEPING when suspended.
ChibiOS/HAL blocking API
ChibiOS/HAL is a crucial part of the ChibiOS project, consisting of a set of device drivers carefully crafted to offer a consistent API across various platforms. Its primary goal is to empower application developers by allowing them to design applications that are mostly independent of the specific hardware they run on. One notable feature of HAL is that is is perfectly coupled with ChibiOS/RT offering a thread ready API.
When a peripheral is enabled, HAL takes over the ISR handling from RT. HAL provides a set of APIs for each driver, known to be blocking. Examples of these APIs include:
/** * SPI Full Duplex Transfer * Performs a full duplex SPI transfer, blocking until operation is complete. */ void spiExchange(SPIDriver *spip, size_t n, const void *txbuf, void *rxbuf); /** * I2C Master Transmit * Transmits data as an I2C master, blocks until completion. */ msg_t i2cMasterTransmit(I2CDriver *i2cp, i2caddr_t addr, const uint8_t *txbuf, size_t txbytes, uint8_t *rxbuf, size_t rxbytes); /** * ADC Conversion * Performs an ADC conversion, blocking until the conversion is completed. */ msg_t adcConvert(ADCDriver *adcp, const ADCConversionGroup *grpp, adcsample_t *samples, size_t depth); /** * DAC Conversion * Performs a DAC conversion, blocking until the conversion is completed. */ msg_t dacConvert(DACDriver *dacp, const DACConversionGroup *grpp, dacsample_t *samples, size_t depth); /** * USB Data Transmit * Transmits data over USB, blocks until the operation is complete. */ size_t usbTransmit(USBDriver *usbp, usbep_t ep, const uint8_t *buf, size_t n); /** * USB Data Receive * Receives data over USB, blocks until data is received. */ size_t usbReceive(USBDriver *usbp, usbep_t ep, uint8_t *buf, size_t n);
These APIs usually utilize Direct Memory Access for transactions, depending on the low-level driver implementation. When called, the API configures the DMA for the transaction and suspends the calling thread. The DMA’s Interrupt Service Routine (ISR) is intercepted by ChibiOS/HAL which calls some RT API to wake up the original thread.
Event API
ChibiOS/RT provides an event API which we’ll delve into more in a future article. This event engine offers an API for waiting on single or multiple events using OR or AND logic.
/** Blocks until any one of the specified events occurs. */ eventmask_t chEvtWaitOne(eventmask_t events); /** Blocks until one or more of the specified events occur. */ eventmask_t chEvtWaitAny(eventmask_t events); /** Blocks until all of the specified events occur. */ eventmask_t chEvtWaitAll(eventmask_t events);
When a thread calls any of these APIs, it is suspended until the required combination of events is signaled from another part of the code (either thread or ISR). This causes the suspended thread to join the ready list. Depending on the API function used, the state of the calling thread is set to either CH_STATE_WTOREVT or CH_STATE_WTALLEVT.
Mutex API
In our previous discussion on Avoiding Race Conditions in ChibiOS/RT: a guide to Mutex, we introduced the concept of Mutex. A Mutex protects shared resources from simultaneous access by multiple threads. If a thread tries to access a resource that is already in use, it calls the chMtxLock() API and gets suspended until the Mutex is released. During this suspension, the calling thread enters the CH_STATE_WTMTX state.
Semaphore API
The Counting Semaphore is another synchronization mechanism in ChibiOS, which is explained in detail in their documentation. Essentially, it manages resources available in limited quantities. A thread can wait for such a resource using the semaphore with this API:
/** Waits for a semaphore counter to become greater than zero, blocks if the semaphore is not available. */ void chSemWait(semaphore_t *sp);
When a thread calls this API, and the resource is unavailable (meaning the semaphore counter is less than or equal to zero), the thread is suspended until another part of the code (like a different thread or an ISR) signals the semaphore, thus increasing the counter. During suspension, the calling thread is in the CH_STATE_WTSEM state.
The scheduling strategy
The scheduling strategy of ChibiOS/RT can be summarized with one statement
The thread with the highest priority that is ready to run will be executed — there are no exceptions to this rule.
In the upcoming sections, we will explore various scheduling scenarios. This exploration will deepen our understanding of the fundamental statement above and demonstrate how to utilize the scheduling strategy in practical application development. We will examine real-case scenarios, each accompanied by pseudo-code and a time analysis to facilitate our discussion.
Example 1: Priority Scheduling
This first example builds on the one we used during our introduction to multithreading. To complete the example, we’ve added two periodic actions in Thread1 and main. These actions perform a simple task: they blink two different LEDs at set intervals.
/*
* Thread1 related declarations
*/
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
(void)arg;
chRegSetThreadName("Thread1");
while (true) {
palToggleLine(LINE_LED_GREEN);
chThdSleepMilliseconds(100);
}
}
/*
* Main thread related declarations
*/
int main(void) {
/* Initial setup for the system. */
halInit();
chSysInit();
/* Starting Thread1. */
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO + 1, Thread1, NULL);
while (true) {
palToggleLine(LINE_LED_RED);
chThdSleepMilliseconds(150);
}
}
The application uses three threads:
mainhas the priorityNORMALPRIO. It’s the initial thread that starts the system, createsidleduring system initialization (chSysInit), and launchesThread1. In its loop,maintogglesLINE_LED_REDand sleeps for 150ms.Thread1has a higher priority (NORMALPRIO + 1). It names itself “Thread1” and alternates theLINE_LED_GREENstatus, pausing for 100ms between each toggle.idlehas the lowest priority (IDLEPRIO). It runs when no other thread is active.
Timing analysis
Next, we will present a timing diagram that illustrates the execution times for each thread. This diagram is straightforward to construct because ChibiOS/RT operates deterministically. Without any randomness and with a known sequence of events, the timing of thread execution is predictable.
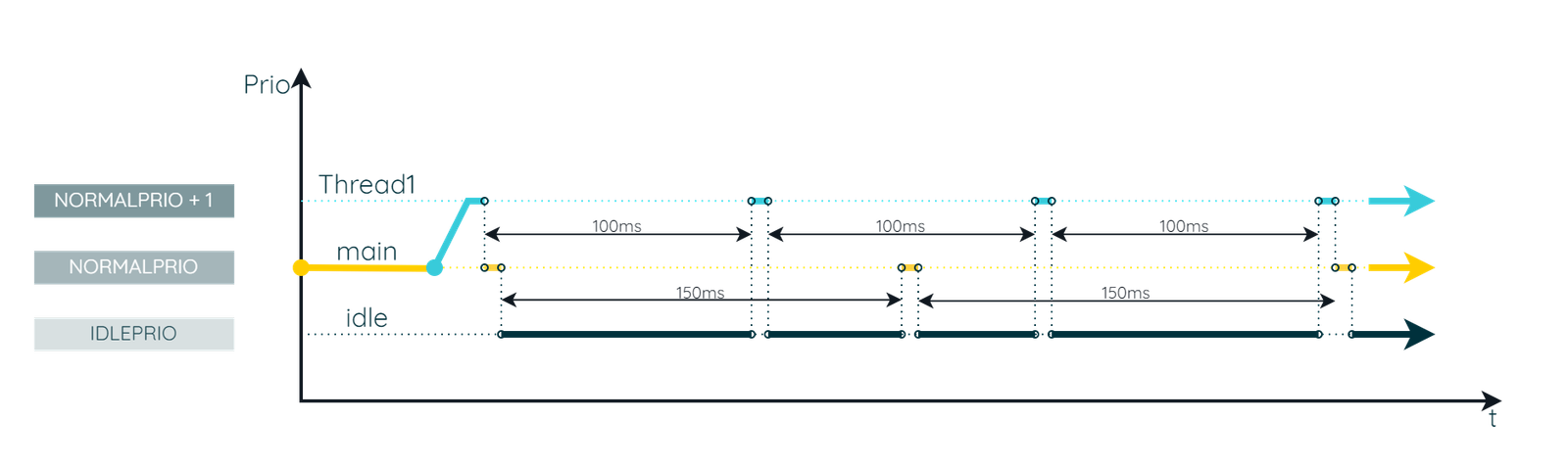
The timing diagram reveals that the main thread runs uninterrupted until Thread1 is created (via chThdCreateStatic). Once Thread1 is in the ready list, it competes with main for CPU time and, due to its higher priority, Thread1 preempts main. Subsequently, the three threads—main, Thread1, and idle—execute in turn according to their respective timings and priority. Please note that the time taken to create Thread1 and the duration of the palToggleLine execution have been intentionally exaggerated for illustrative purposes as will be shown in the next paragraph.
Note on palToggleLine execution
An important detail to note is that the instruction palToggleLine should be barely visible within the timing diagram. This instruction’s impact is minimal because it simply reads a memory location, toggles a single bit, and writes back the result. Translated into assembly language for an ARM Cortex-M processor, the process resembles the following:
LDR R0, =LINE_LED_RED ; Load LINE_LED_RED into R0
AND R1, R0, #0xFFFFFFF0 ; Mask to get the register address
AND R2, R0, #0xF ; Mask to get the bit position
LDR R3, [R1] ; Load the value from the register address
MOV R4, #1 ; Load 1 into R4
LSL R4, R4, R2 ; Shift left by bit position
EOR R3, R3, R4 ; Toggle the bit in R3
STR R3, [R1] ; Store the value back to the register
This sequence takes approximately 10 CPU cycles, which translates to about 100 nanoseconds of execution time on a CPU running at 100 MHz. This duration is negligible compared to the shortest sleep duration in our scenario, which is 100 milliseconds. In this example, the CPU is predominantly in the IDLE state, accounting for an average CPU usage of just about 0.01%.
Example 2: Coercitive Round Robin
In applications where threads share the same priority level, we encounter a scenario called Coercive Round Robin. In this mode, the scheduler allocates CPU time to each thread in sequence.
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
(void)arg;
chRegSetThreadName("Thread1");
while (true) {
/*
...
Operation block requires (75ms)
...
*/
}
}
static THD_WORKING_AREA(waThread2, 128);
static THD_FUNCTION(Thread2, arg) {
(void)arg;
chRegSetThreadName("Thread2");
while (true) {
/*
...
Operation block requires (25ms)
...
*/
}
}
static THD_WORKING_AREA(waThread3, 128);
static THD_FUNCTION(Thread3, arg) {
(void)arg;
chRegSetThreadName("Thread3");
while (true) {
/*
...
Operation block requires (50ms)
...
*/
}
}
int main(void) {
halInit();
chSysInit();
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO, Thread1, NULL);
chThdCreateStatic(waThread2, sizeof(waThread2), NORMALPRIO, Thread2, NULL);
chThdCreateStatic(waThread3, sizeof(waThread3), NORMALPRIO, Thread3, NULL);
while (true) {
/*
...
Operation block requires (100ms)
...
*/
}
}
The application involves four threads operating at NORMALPRIO, in addition to the idle thread. Notably, each thread performs a distinct periodic task that takes a varying duration to complete. None of these tasks involve calling functions that would release the CPU.
However, Coercive Round Robin is activated in chconf.h with a time quantum configured to be 50ms. Details on this configuration are provided at the conclusion of this example, allowing us to concentrate on the timing analysis for now.
Timing analysis
The timing diagram will show that each thread is allotted precisely 50ms of runtime before being preempted, even if this interrupts an operation.
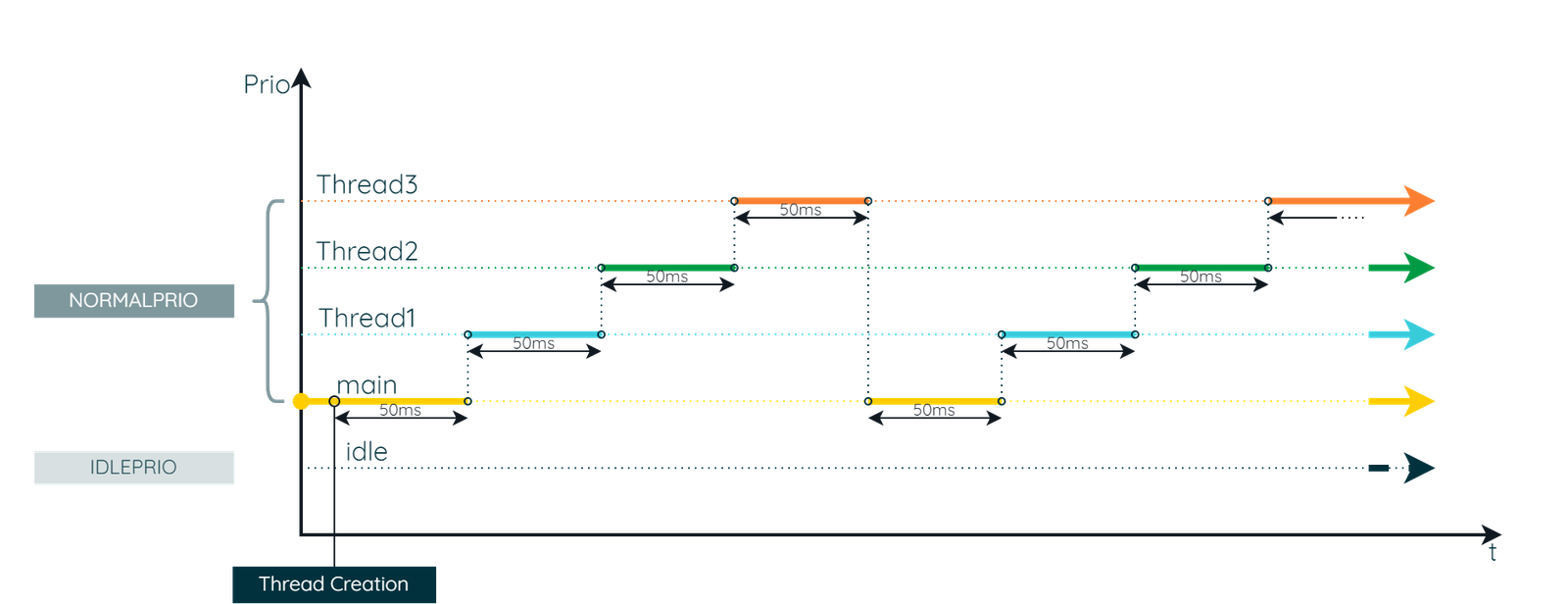
In this scenario, the idle thread will never run, as all other threads are always either executing (CH_STATE_CURRENT) or ready to execute (CH_STATE_READY).
How to configure the time quantum
The time quantum for Coercive Round Robin is set in chconf.h, defined in system ticks with the parameter CH_CFG_TIME_QUANTUM.
/** * @brief Round robin interval. * @details This constant is the number of system ticks allowed for the * threads before preemption occurs. Setting this value to zero * disables the preemption for threads with equal priority and the * round robin becomes cooperative. Note that higher priority * threads can still preempt, the kernel is always preemptive. * @note Disabling the round robin preemption makes the kernel more compact * and generally faster. * @note The round robin preemption is not supported in tickless mode and * must be set to zero in that case. */ #if !defined(CH_CFG_TIME_QUANTUM) #define CH_CFG_TIME_QUANTUM 500 #endif
In this instance, we’ve set the quantum to 500 System Ticks. As previously mentioned, the OS tick frequency is configurable, with the default set at 10kHz (CH_CFG_ST_FREQUENCY equals 10000), which equates to a tick period of 100us. Consequently, 500 ticks amount to a 50ms quantum.
To conclude, it’s crucial to understand that Coercive Round Robin is only feasible when tick mode is active. While it’s a viable scheduling option, it is not typically favored due to potential inefficiencies in CPU utilization. Tasks may be interrupted frequently, which can lead to decreased performance in time-sensitive applications.
Example 3: Cooperative Round Robin
This example shows a more convenient way to handle threads at same priority. It is a variation of the previous one and in this case CH_CFG_TIME_QUANTUM is set to 0 which means that the round robin preemption is disabled. However the situation in term of priorities remains the same. We still have 4 threads at same priority each one performing a blocking operation in its loop. If the thread that runs first (main in this case) is not releasing the CPU then the other threads will never have the chance to run: they would stay ready forever in the ready list without being executed once.
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
(void)arg;
chRegSetThreadName("Thread1");
while (true) {
/*
...
Operation block requires (75ms)
...
*/
chThdYield();
}
}
static THD_WORKING_AREA(waThread2, 128);
static THD_FUNCTION(Thread2, arg) {
(void)arg;
chRegSetThreadName("Thread2");
while (true) {
/*
...
Operation block requires (25ms)
...
*/
chThdYield();
}
}
static THD_WORKING_AREA(waThread3, 128);
static THD_FUNCTION(Thread3, arg) {
(void)arg;
chRegSetThreadName("Thread3");
while (true) {
/*
...
Operation block requires (50ms)
...
*/
chThdYield();
}
}
int main(void) {
halInit();
chSysInit();
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO, Thread1, NULL);
chThdCreateStatic(waThread2, sizeof(waThread2), NORMALPRIO, Thread2, NULL);
chThdCreateStatic(waThread3, sizeof(waThread3), NORMALPRIO, Thread3, NULL);
while (true) {
/*
...
Operation block requires (100ms)
...
*/
chThdYield();
}
}
This type of scheduling is called Cooperative Round Robin for a reason: in this case each thread voluntarily releases the CPU after performing its operations calling the API chThdYield(). When a thread that yields, it moves from the state CH_STATE_CURRENT to the state CH_STATE_READY and it is moved at the end of the ready list. This means that the next thread in the list will be resumed and that the thread that yielded will need to wait an entire round before being executed again.
Timing analysis
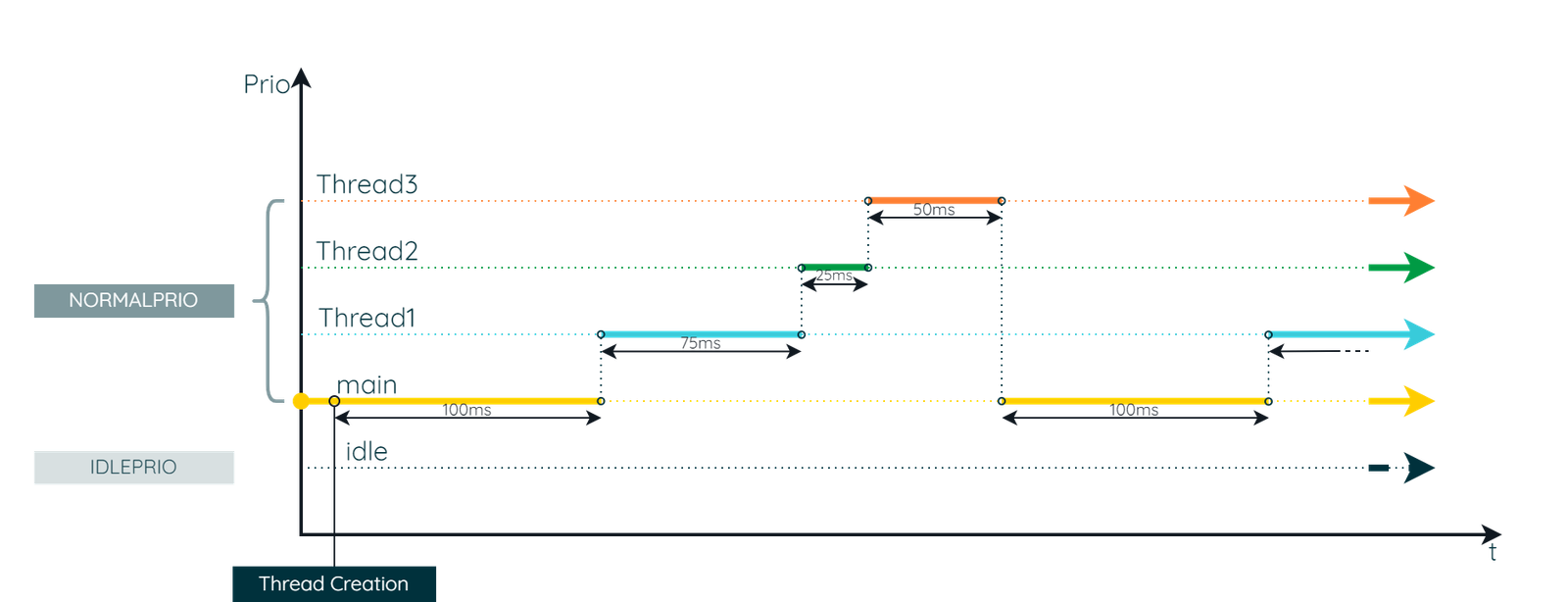
In this case each thread executes the entire operation block before voluntarily yielding. As we can see the threads are still running in a Round Robin but the time slice is variable and depends on the length of the operation block of each thread.
Example 4: Mixed scenario
In this mixed scenario, we delve into an advanced application of Cooperative Round Robin. We have two threads (main and Thread2) operating under Cooperative Round Robin, and a third thread (Thread1) at a higher priority level. Thread1‘s function, derived from the article Mastering push buttons with ChibiOS PAL: Hands-on exercises, involves waiting for the press of a button (an external event) to toggle an LED.
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
(void)arg;
chRegSetThreadName("Thread1");
/* Setting the button line as digital input without pull resistors. */
palSetLineMode(LINE_EXT_BUTTON, PAL_MODE_INPUT);
/* Enabling the event on the Line for a Rising edge. */
palEnableLineEvent(LINE_EXT_BUTTON, PAL_EVENT_MODE_RISING_EDGE);
while (true) {
/* Waiting for the even to happen. */
palWaitLineTimeout(LINE_EXT_BUTTON, TIME_INFINITE);
/* Our action. */
palRoggleLine(LINE_LED_GREEN);
}
}
static THD_WORKING_AREA(waThread2, 128);
static THD_FUNCTION(Thread2, arg) {
(void)arg;
chRegSetThreadName("Thread2");
while (true) {
/*
...
Operation block requires (75ms)
...
*/
chThdYield();
}
}
int main(void) {
halInit();
chSysInit();
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO + 1, Thread1, NULL);
chThdCreateStatic(waThread2, sizeof(waThread2), NORMALPRIO, Thread2, NULL);
while (true) {
/*
...
Operation block requires (50ms)
...
*/
chThdYield();
}
}
Timing analysis
What happens in this scenario?
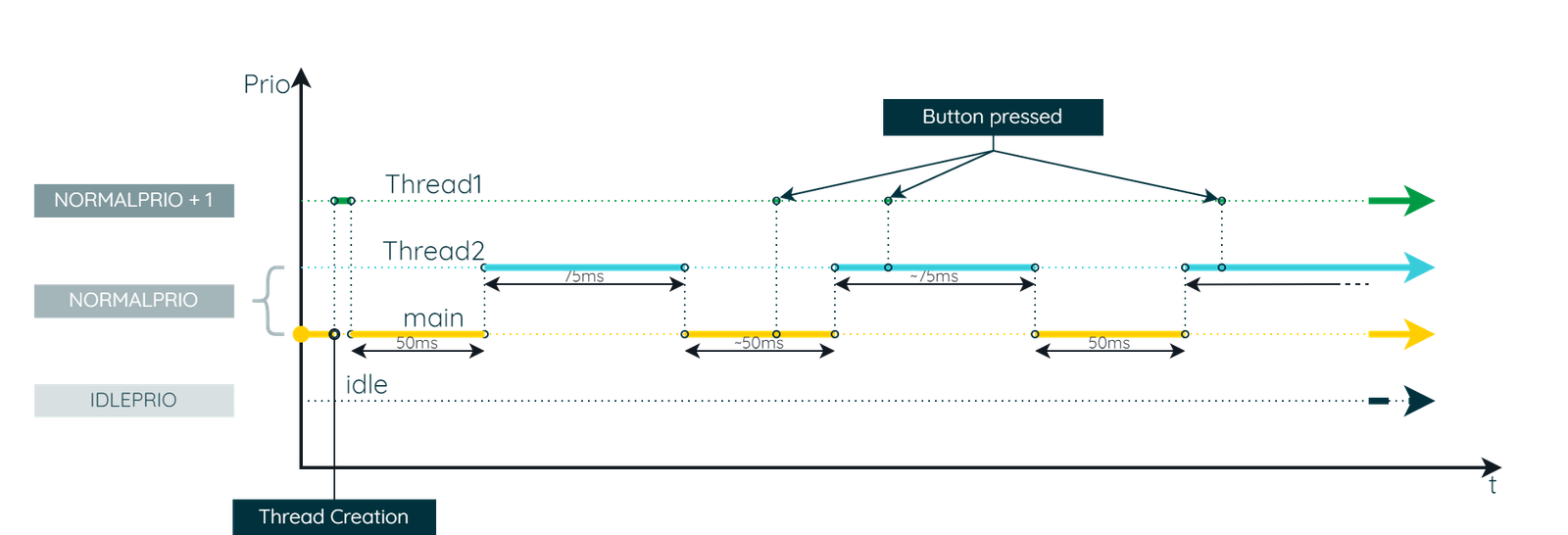
The main thread and Thread2 alternate CPU time through Round Robin until the button is pressed. In the moment the user presses the button, Thread becomes ready and, due to its higher priority, it preempts the currently running thread to execute its task. Once Thread1 is suspended waiting for the next event, the Round Robin between main and Thread2 picks up where it left off.
Additional consideration on the priority selection
It’s crucial to understand the implications of priority levels. If Thread1 had a lower priority than the others, it would not get a chance to execute since main and Thread2 do not relinquish the CPU. This serves as a cautionary note on how improper priority assignments can disrupt your scheduling strategy, potentially leading to application malfunction or loss of real-time performance.
As a guideline, threads that fully block should be assigned the same priority and designed to yield, permitting equal CPU time to other threads at the same level. These threads should also have the lowest priority possible so that the Round Robin happens when no other thread is ready. Threads that require prompt responses to events should be given higher priority, with a focus on optimizing their operations to prevent prolonged CPU blocking, which could delay the execution of other threads.
Example 5: Priority inversion and priority inheritance
This example is critical as it introduces the well-known issue of Priority Inversion, which occurs when two threads of different priorities access the same resource. Uncoordinated access can lead to a Race Condition. To mitigate this, threads must synchronize access to shared resources using a Mutex.
A quick recap about Mutex
The concepts of race conditions and mutexes are extensively covered in Avoiding Race Conditions in ChibiOS/RT: a guide to Mutex. However let us recall briefly the concepts.
A mutex allows for the creation of a mutual exclusion zone within threads. Consider the following code where two threads synchronize using a mutex:
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
(void) arg;
while (true) {
/* Begin of the mutual exclusive zone. */
chMtxLock(&my_mutex);
/* Mutual exclusion zone. */
chMtxUnlock(&my_mutex);
/* End of the mutual exclusive zone. */
chThdSleepMilliseconds(100);
}
}
static THD_WORKING_AREA(waThread2, 128);
static THD_FUNCTION(Thread2, arg) {
(void) arg;
while (true) {
/* Begin of the mutual exclusive zone. */
chMtxLock(&my_mutex);
/* Mutual exclusion zone. */
chMtxUnlock(&my_mutex);
/* End of the mutual exclusive zone. */
chThdSleepMilliseconds(100);
}
}
In this setup, each thread has its own mutual exclusion zone. Essentially, a thread can enter its mutual exclusion zone only if the other thread is not already inside its zone. This means that the two threads cannot be in their mutual exclusion zones simultaneously.
If a thread attempts to lock the mutex with chMtxLock while it is already locked, it will be suspended in the CH_STATE_WTMTX state until the mutex is released.
Study case
In this scenario, we are intentionally using high CPU to clearly demonstrate Priority Inversion. While the issue is less obvious in real-world situations, it’s still a significant concern.
Let’s examine the code:
static ch_mutex_t mxt;
static THD_WORKING_AREA(waThread1, 128);
static THD_FUNCTION(Thread1, arg) {
(void)arg;
chRegSetThreadName("Thread1");
while (true) {
/*
...
Operation block requires (25ms)
...
*/
chThdSleepMilliseconds(50);
}
}
static THD_WORKING_AREA(waThread2, 128);
static THD_FUNCTION(Thread2, arg) {
(void)arg;
chRegSetThreadName("Thread2");
while (true) {
/*
...
Operation block requires (50ms)
...
*/
chThdSleepMilliseconds(50);
}
}
static THD_WORKING_AREA(waThread3, 128);
static THD_FUNCTION(Thread3, arg) {
(void)arg;
chRegSetThreadName("Thread3");
while (true) {
/* Begin of the mutual exclusive zone. */
chMtxLock(&mxt);
/* Operation on shared resources that 75ms. */
chMtxUnlock(&mxt);
/* End of the mutual exclusive zone. */
chThdSleepMilliseconds(50);
}
}
int main(void) {
halInit();
chSysInit();
chMtxObjectInit(&mxt);
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO - 1, Thread1, NULL);
chThdCreateStatic(waThread2, sizeof(waThread2), NORMALPRIO - 2, Thread2, NULL);
chThdCreateStatic(waThread3, sizeof(waThread3), NORMALPRIO - 3, Thread3, NULL);
chThdSleepMilliseconds(125);
while (true) {
/* Begin of the mutual exclusive zone. */
chMtxLock(&mxt);
/* Operation on shared resources that 25ms. */
chMtxUnlock(&mxt);
/* End of the mutual exclusive zone. */
chThdSleepMilliseconds(200);
}
}
We have four threads plus idle, each at a different priority. Excluding idle, the main and Thread3 are at opposite ends of the scale and share a resource protected by a mutex. In this example, all operation blocks are CPU-intensive to highlight the issue.
The sleep following the thread creation is intentional. It ensures that Thread3 starts and locks the mutex before the main thread can. Let’s examine the consequences of this setup.
Priority Inversion
If main attempts to lock the Mutex while Thread3 has it locked, it must wait until Thread3 releases the resource. In this scenario, main is not only blocked by Thread3, but Thread3 itself is repeatedly preempted by Thread1 and Thread2, which have higher priorities. Let’s illustrate this with the timing diagram.
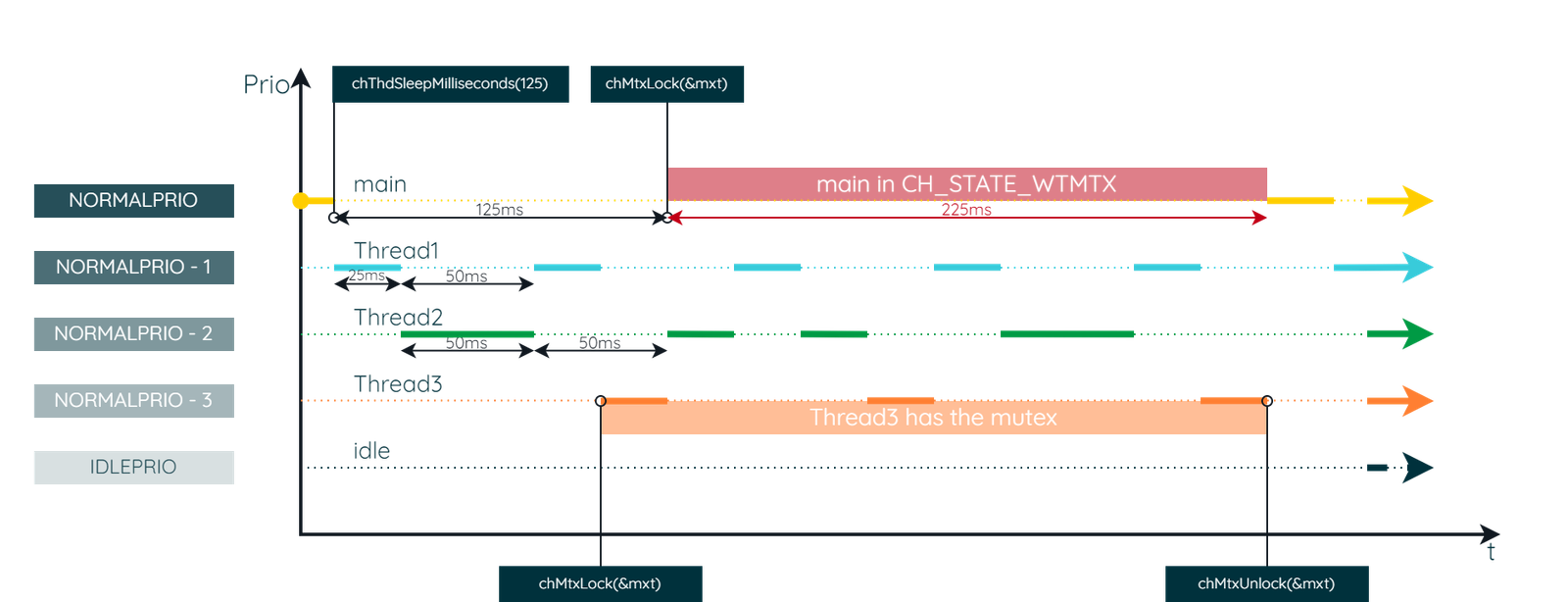
This dynamic creates a situation known as Priority Inversion. Essentially, main is forced to operate at an effectively lower priority than Thread3 until the shared resource is released. .
Priority Inheritance
The timing diagram described above is hypothetical. ChibiOS/RT addresses the Priority Inversion by implementing what is known as Priority Inheritance. When main attempts to acquire the mutex and finds the mutex held by Thread3, Thread3 temporarily inherits the higher priority of main. Consequently, Thread3 is not preempted by Thread1 and Thread2. Once Thread3 releases the mutex with spiReleaseBus, the original priorities are restored, and main resumes execution. The following timing diagram illustrates this mechanism.
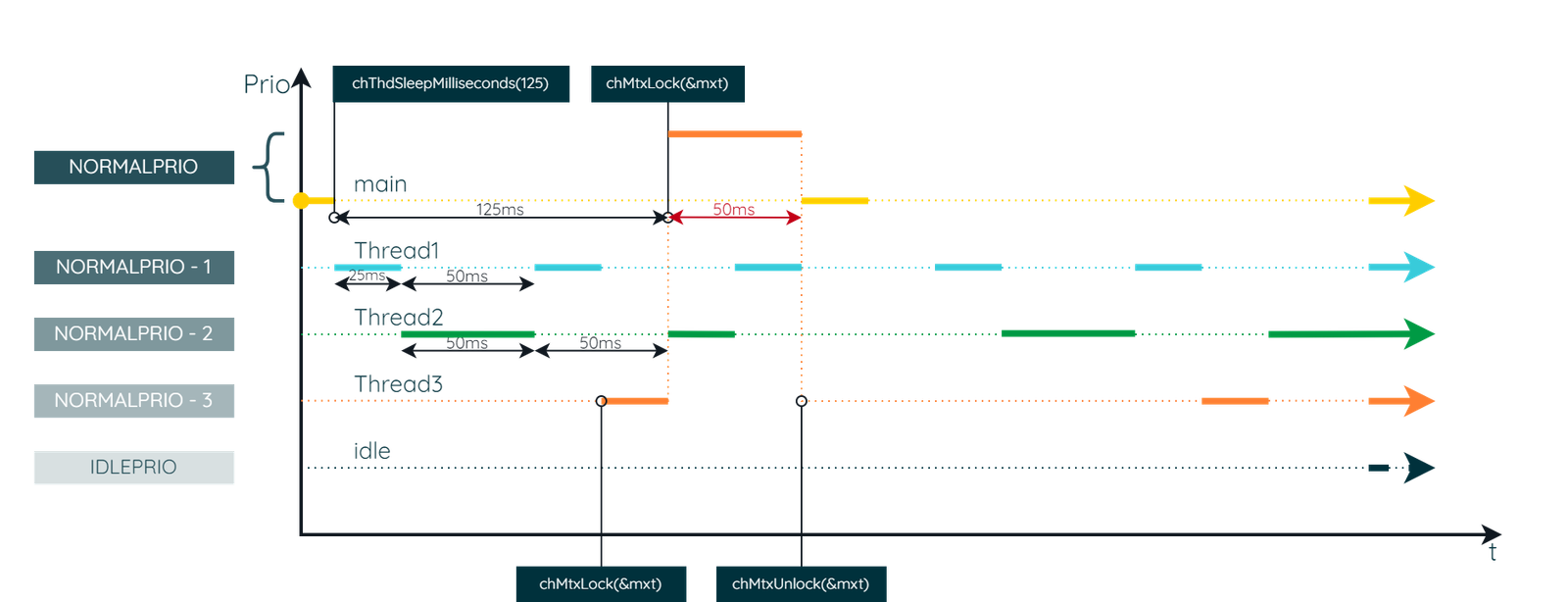
It’s important to note that in ChibiOS/RT, mutexes implement the priority inheritance mechanism, whereas semaphores do not. Additionally, it’s important to emphasize that real applications should minimize blocking operations. Often, time-consuming operations like IO transactions are supported by DMA. This allows the thread initiating the operation to quickly relinquish the CPU, enabling other threads to run. This example deliberately exaggerates to demonstrate how Priority Inheritance benefits the higher-priority main thread by reducing its wait time for the mutex.
Conclusions
Throughout this article, we have seen how the selection of priorities and the use of specific function calls can greatly influence thread scheduling. This understanding is crucial in the realm of Real Time systems. It brings us to a vital conclusion:
An RTOS like ChibiOS/RT is not a silver bullet. Its adoption doesn’t automatically ensure that your system is real-time.
An RTOS it is better thought of as a tool. In this analogy, even the finest screwdriver won’t do much good if used for driving nails instead of screws.
Thanks a lot for this article, with very clear explanations and well developed diagrams!
Thanks for your comment Joaquin. This is the feedback I needed to know that the direction is right.
Thank you very much for this article. It is a great help as I am starting to learn about embedded RT development.
Cool! Enjoy the learning process